Claudes Reise zur Torheit in Diagrammen: Die Kosten der Sparsamkeit oder wie die API-Rechnung um das 100-Fache anstieg
Vor einigen Tagen veröffentlichte Stella Laurenzo, Leiterin der KI bei AMD, ein Problem mit dem Titel "Claude Code für komplexe Ingenieurtasks unbrauchbar" im offiziellen Repository von Claude Code. Dies war keine emotionale Beschwerde eines Nutzers, sondern eine quantitative Analyse basierend auf 6.800 Sitzungen. Es brachte das am wenigsten gewollte Problem der KI-Community ans Licht, wobei eine Zahlenreihe besonders herausstach: Eine kostensparende Konfigurationseinstellung von Anthropic ließ die monatliche API-Rechnung dieses Teams von 345 $ auf 42.121 $ in die Höhe schnellen.
Laurenzos Team verfolgte 235.000 Tool-Aufrufe, 18.000 Eingabeaufforderungen und dokumentierte die systematische Leistungsverschlechterung des Claude Codes seit Februar 2026. Dieser Bericht wurde später von The Register aufgegriffen, was einen zweiwöchigen Sturm der öffentlichen Meinung in der Entwicklergemeinschaft auslöste.
Boris Cherny, Leiter des Anthropic Claude Code-Teams, gab eine Erklärung auf Hacker News ab. Am 9. Februar wurde mit der Veröffentlichung von Opus 4.6 ein "selbstdenkend" Mechanismus standardmäßig aktiviert, bei dem das Modell autonom die Denkzeit bestimmt. Am 3. März senkte Anthropic dann den standardmäßigen Denkaufwand auf 85. Die offizielle Erklärung lautete: "der optimale Balancepunkt zwischen Intelligenz, Latenz und Kosten." Die tatsächlichen Auswirkungen dieser beiden Anpassungen sind aus den Daten ersichtlich.
Die Denktiefe fällt um drei Viertel
Laut den GitHub-Issuedaten von Stella Laurenzo erlebte die durchschnittliche Denktiefe des Claude Codes über zwei Monate einen dreistufigen Zusammenbruch: von einem Höchststand von 2.200 Zeichen Ende Januar auf 720 Zeichen bis Ende Februar, ein Rückgang um 67 %. Im März schrumpfte sie weiter auf 560 Zeichen, ein Rückgang um 75 % vom Höchststand.
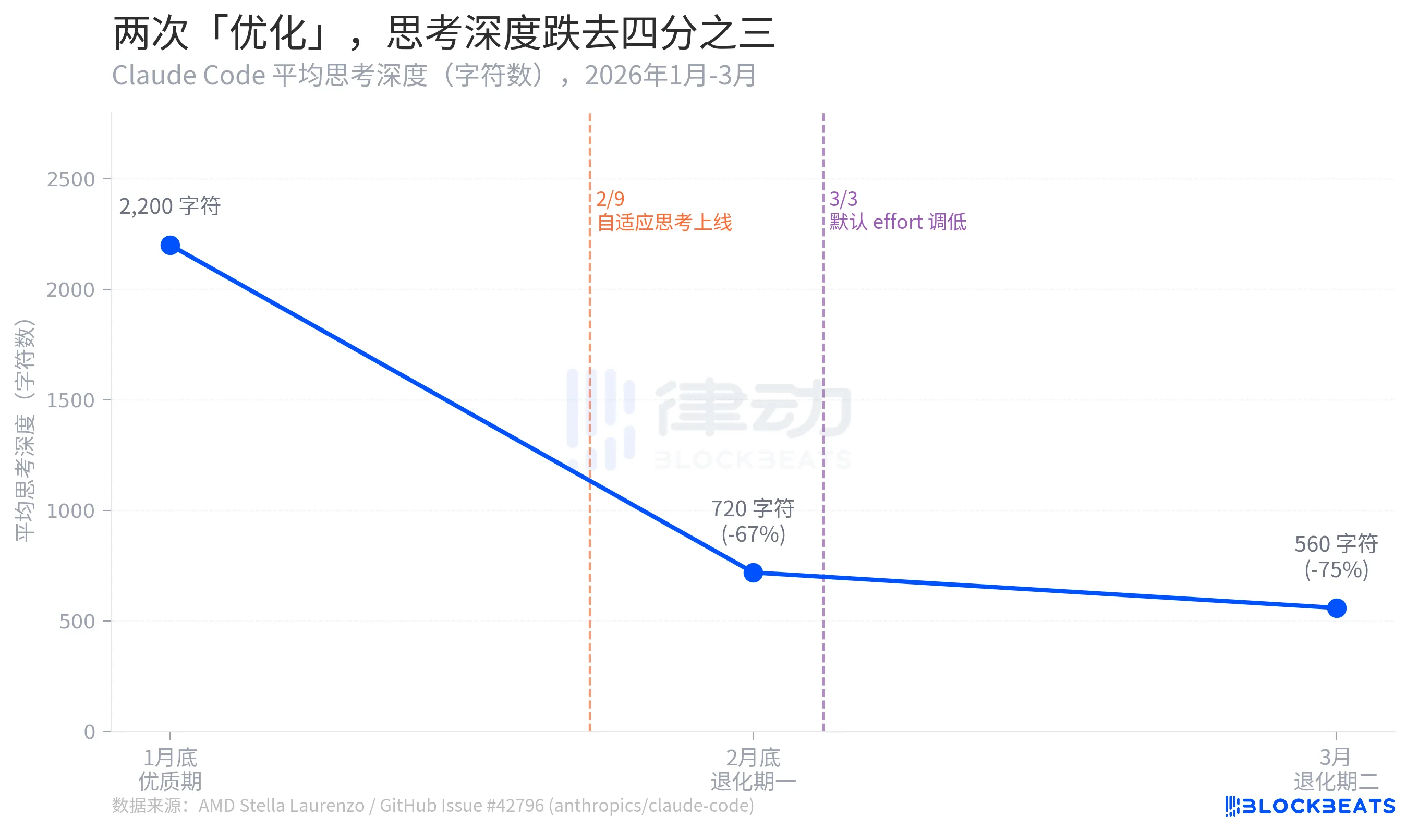
Die Denktiefe hier ist eine Proxy-Metrik, die widerspiegelt, wie viel "interne Überlegung" das Modell bereit ist, anzustellen, bevor es eine Antwort gibt. Der Unterschied zwischen 2.200 und 560 Zeichen entspricht ungefähr dem Abbau von "Entwurf vor der Antwort" zu "zwei Sekunden im Kopf nachdenken, bevor man spricht."
Laurenzo wies auch darauf hin, dass die Funktion "Inhaltsredaktion des Denkens" (redact-thinking-2026-02-12), die Anfang März eingeführt wurde, zufällig den Denkprozess des Modells in diesem Zeitraum maskierte, wodurch die Schrumpfung für die Nutzer weniger wahrnehmbar wurde. Boris Cherny besteht darauf, dass dies lediglich eine UI-Änderung war und did-133">nicht die zugrunde liegende Argumentation beeinflusste. Beide Behauptungen sind technisch gültig, aber aus der Perspektive eines Nutzers ist die Wirkung nicht unterscheidbar.
Boris Cherny erkannte später an, dass selbst wenn der Aufwand manuell auf maximal gesetzt wird, der Selbstdenker-Mechanismus in einigen Runden möglicherweise immer noch unzureichende Argumentation zuweist, was zu halluzinatorischen Inhalten führt. "Die Wiederherstellung des maximalen Aufwands" ist keine vollständige Lösung; sie dreht lediglich den Regler näher an seine ursprüngliche Position zurück, anstatt ihn zu seinem ursprünglichen Determinismus wiederherzustellen.
Von "Forschungsorientiertem Programmierer" zu "Blindem Editierprogrammierer"
Ein Detail in Stella Laurenzo's Bericht ist expliziter als die Denktiefe: wie viele relevante Dateien das Modell aktiv liest, bevor es Änderungen am Code vornimmt.
Laut den GitHub-Issue-Daten liegt das durchschnittliche Verhältnis von Lesen zu Bearbeiten während der Hauptphase bei 6,6. Bevor eine Codeänderung vorgenommen wird, liest das Modell im Durchschnitt 6,6 Dateien, um den Kontext zu verstehen. Während der Abklingphase sinkt diese Zahl auf 2,0, was einem Rückgang von 70 % entspricht. Kritischer ist, dass etwa ein Drittel der Codeänderungen erfolgt, ohne dass das Modell die Zieldatei liest, sondern direkt einsteigt.
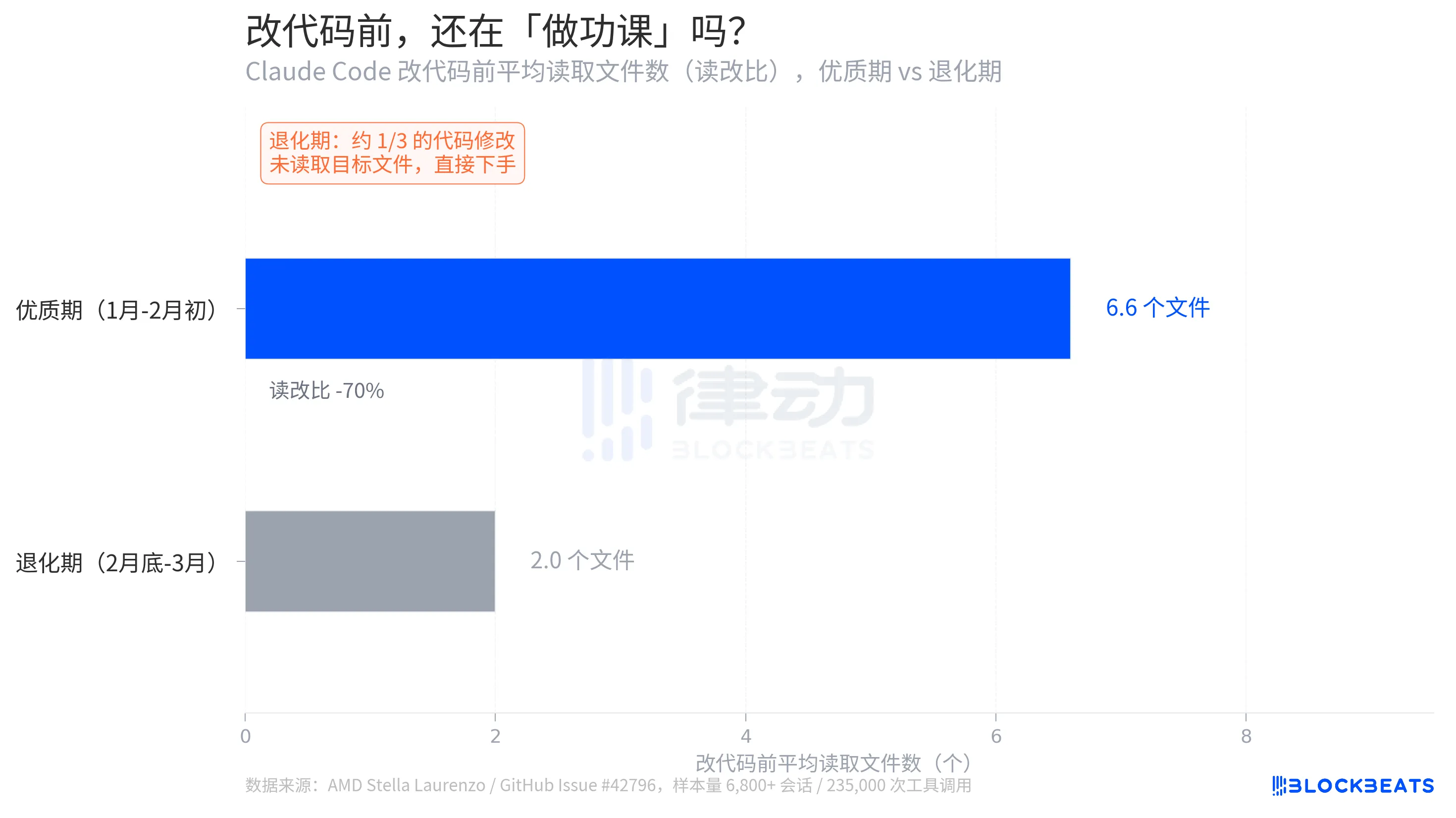
Laurenzo bezeichnet dies als "blinde Änderungen." In ingenieurtechnischen Begriffen ist dies vergleichbar mit einem Programmierer, der Code schreibt, ohne sich die Funktionssignaturen anzusehen oder die Variablentypen zu kennen. "Jeder Senior Engineer in meinem Team hat ähnliche Erfahrungen aus erster Hand gemacht," schrieb sie in ihrem Bericht. "Claude kann nicht mehr vertraut werden, um komplexe Ingenieuraufgaben auszuführen."
Der Rückgang von einem Verhältnis von 6,6 zu 2,0 ist nicht nur eine Verhaltensmetrikenverschiebung; er bedeutet einen Zusammenbruch der Erfolgsraten von Aufgaben. Die Komplexität moderner Code-Repositories erfordert, dass jede Änderung Abhängigkeiten über mehrere Dateien hinweg umfasst. Das Überspringen der Kontextexploration und das direkte Vornehmen von Änderungen führt nicht nur zu "falschen Antworten", sondern zu "scheinbar korrekten Änderungen, die neue Fehler nach sich ziehen." Die Kosten für das Debuggen solcher Fehler übersteigen bei weitem die Kosten für eine einzige fehlgeschlagene explizite Antwort.
Das Paradoxon des "Geldsparens"
Eine der kontraintuitivsten Zahlenmengen in dem gesamten Vorfall stammt aus denselben GitHub-Issue-Daten: Stella Laurenzo's Team sah die monatlichen Kosten für die Nutzung der Claude Code API von 345 $ im Februar 2026 auf beeindruckende 42.121 $ im März sinken, was einem Anstieg um das 122-Fache entspricht.
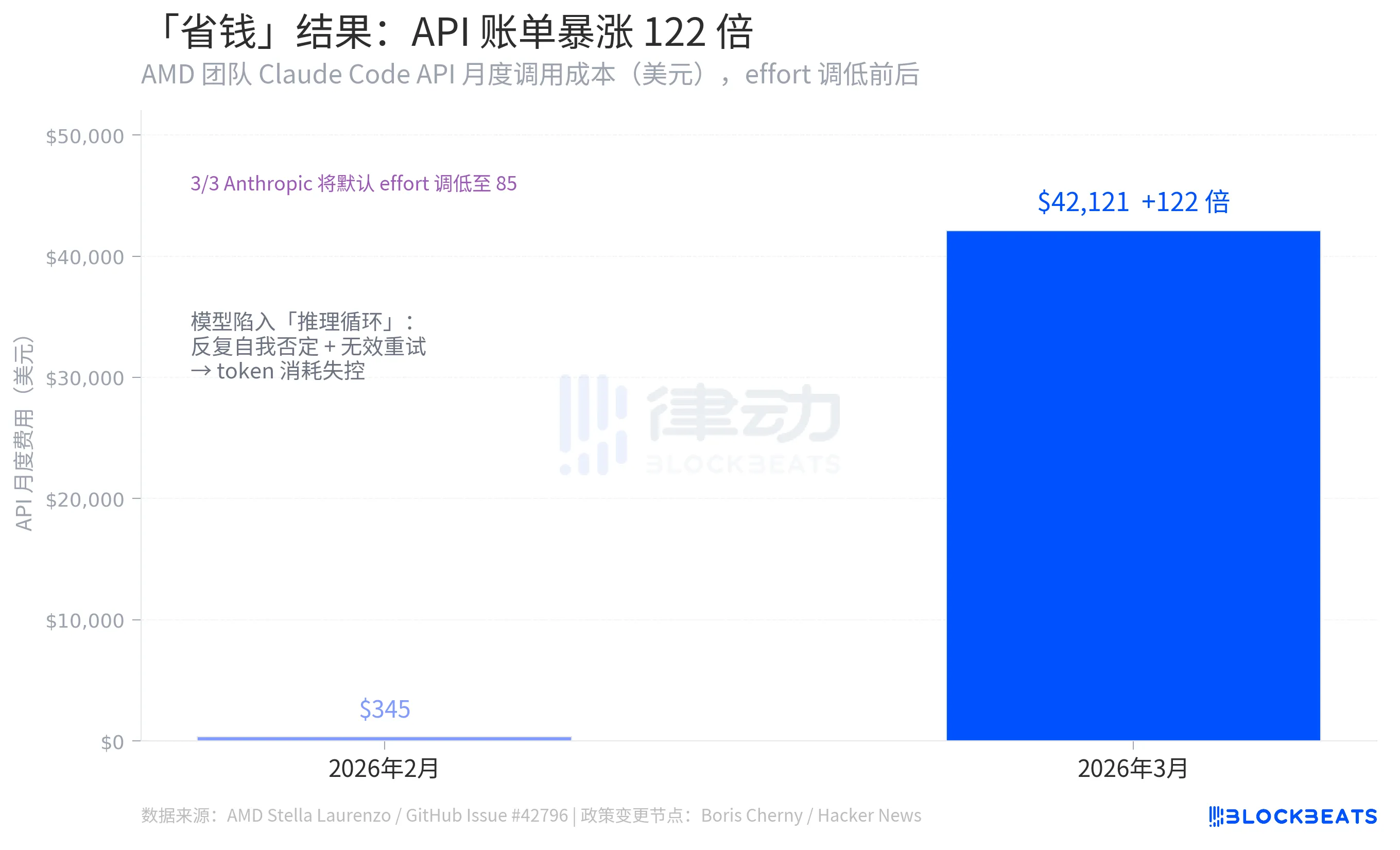
Die Logik hinter der Reduzierung des Aufwands von Anthropics bestand darin, den Tokenverbrauch pro Aufruf zu senken und somit die Kosten zu reduzieren. Das Ergebnis war jedoch das Gegenteil. Der Grund dafür war das Auftreten zahlreicher "Denkschleifen" nach dem Verfall des Modells, was zu wiederholter Selbstnegation innerhalb einer einzigen Antwort, ständigen Neustarts und einem Tokenverbrauch führte, der die eingesparte Menge bei weitem überstieg. Laut den Daten von Stella Laurenzo stieg die Rate der Benutzer, die Aufgaben freiwillig abbrachen, im gleichen Zeitraum um das 12-Fache, was kontinuierliches Eingreifen, Korrekturen und erneute Einreichungen durch die Entwickler erforderte.
Die zugrunde liegende Logik ist ein systematischer Fehler. Die Reduzierung der Rechenleistung bei einer komplexen Aufgabe senkt nicht einfach proportional die Kosten. Sobald ein gewisser Denkthreshold unterschritten wird, beginnt das Modell, vom Kurs abzukommen, und die Gesamtkosten steigen letztendlich. Die Senkung des Aufwands sparte Geld bei einfachen Anfragen, aber bei Programmieraufgaben explodierte die Rechnung.
Die "Vereinfachung"-Sache, die GPT-4 vor drei Jahren gemacht hat.
Im Juli 2023 veröffentlichte ein Forschungsteam der Stanford University und der University of California, Berkeley, ein Papier auf arXiv mit dem Titel "Wie verändert sich das Verhalten von ChatGPT im Laufe der Zeit?", das dasselbe Phänomen dokumentierte, das bei GPT-4 auftrat.
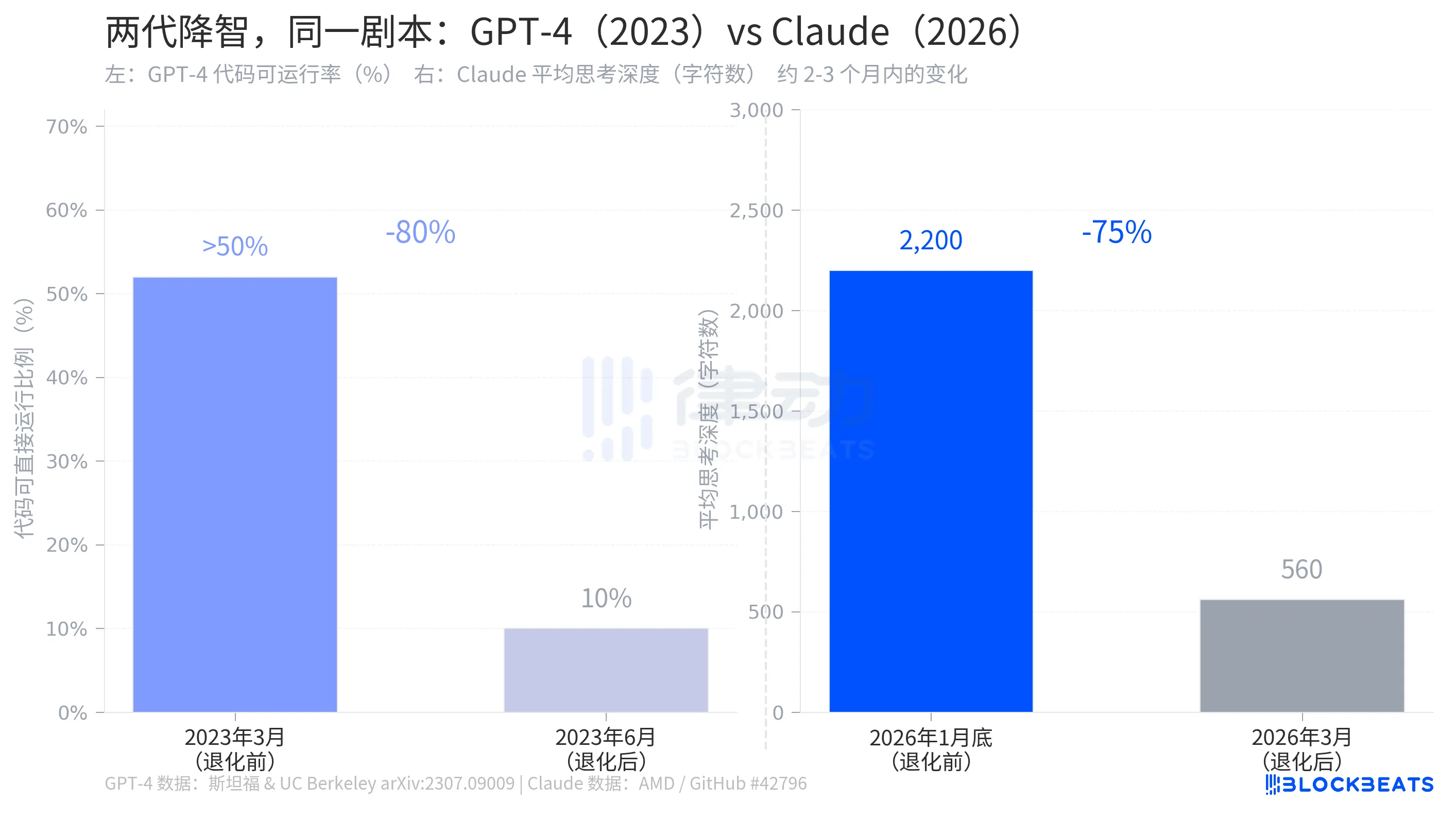
Laut den Forschungsdaten hatte GPT-4 im März 2023 Code generiert, bei dem über 50 % direkt ausführbar waren. Bis Juni war dieser Anteil auf 10 % gesunken, was einem Rückgang um 80 % innerhalb von drei Monaten entspricht. Im gleichen Zeitraum fiel die Genauigkeit bei der Identifizierung von Primzahlen von 97,6 % auf 2,4 %. Die Reaktion von OpenAI war der von Anthropic sehr ähnlich: Es hatte Optimierungen im Hintergrund gegeben, die Teil der normalen Iteration waren.
Die Struktur der beiden Geschichten ist nahezu identisch: Ein KI-Unternehmen passte im Hintergrund stillschweigend Parameter an, die die Fähigkeiten des Modells beeinflussten, die Benutzer bemerkten es, das Unternehmen erkannte die Anpassung an, erklärte sie jedoch als "vernünftigere Ressourcenzuteilung." Die Verschlechterung von GPT-4 trat 2023 auf, die von Claude geschah 2026, drei Jahre auseinander, aber das Skript ist dasselbe.
Dies ist kein spezifischer Fehler eines Unternehmens. Die wirtschaftliche Logik von KI-Abonnementmodellen bestimmt, dass Hersteller unter dem gleichen Druck stehen, wenn die Kosten für das Denken die Preise übersteigen, die gedeckt werden können. Die Senkung der standardmäßigen Denkintensität ist derzeit der einfachste Hebel, um zwischen Kosten und Leistung zu steuern. Was die Benutzer wahrnehmen, ist das Modell, das "dümmer" wird. Was der Hersteller in den Büchern spart, ist die marginale Token-Kosten pro Anruf.
Boris Cherny hat eine technische Lösung bereitgestellt, bei der Benutzer die Gedankenintensität manuell auf das höchste Niveau über den Befehl /effort high oder durch Modifikation der Konfigurationsdatei wiederherstellen können. Diese Lösung ist technisch machbar, bedeutet jedoch auch, dass "maximale Leistung" nicht mehr die Standardeinstellung ist.
Von 345 $ bis 42.121 $ war das, was ausgegeben wurde, nicht nur das Budget, sondern auch eine Annahme: Die vom Hersteller vorgenommenen Änderungen an der Standardkonfiguration sollten die Benutzererfahrung verbessern.
Das könnte Ihnen auch gefallen

Sind es Hacker und Regulierungsbehörden, die DeFi ruiniert haben?

He Yidengs Rang: Wenn du schon einmal hier bist, kannst du es auch versuchen

Sechs große Kritikpunkte eines Ethereum-Entwicklers

WEEX GOGOGO Folge 3|LALIGA Road to Gold – 6 explosive Momente, 1 WM-Ticket und eine Nacht, die niemand vergessen wird

2 Jahre, 225-fache Rendite? Wir enthüllen die KI-„Flaschenhals“-Anlagestrategie des mysteriösen Forschers Serenity

B.AI kooperiert mit BNB Chain zum Start der „Billion AI Token Subsidy“-Feier und entfacht das On-Chain-Ökosystem für intelligente Agenten

Der Billionen-Dollar-Rausch beim Speicherverkauf: Gewinne beim Speicherkauf halbiert

Morgenbericht | Binance startet DYOR-Recherche-Tool; YZi Labs startet Rekrutierungsplattform YZi Talent; Vitalik erklärt, dass die Ethereum Foundation „verkleinern“ und den Verkauf von ETH reduzieren wird

Der Mars-Traum von SuperEx: Digitale Währungen als Schlüssel für den wirtschaftlichen Austausch im interstellaren Zeitalter

Morgennachrichten | Michael Saylor gab an, diese Woche Anleihen statt Bitcoin gekauft zu haben; StablR wurde angegriffen und verlor etwa 2,8 Millionen Dollar; der US-Kongress treibt den Bitcoin Reserve Act erneut voran
Wichtigste Erkenntnisse: Volltext der Rede von Google-Chef-Wissenschaftler Shanahan

Agentic Design Patterns: Ein Buch, das mich dazu brachte, „Was genau ist ein Agent?“ zu überdenken

Der reichste Fed-Chef seit 112 Jahren ist da: Kevin Warsh schreibt die Regeln neu

Vitalik über die Zukunft der Ethereum Foundation: Ein kleineres, markanteres und beständigeres Schiff

Neue Formen der Informationswäsche auf Prognosemärkten: Wie Geheimnisse in Investitionssignale einfließen

WEEX Bitcoin Pizza Day: Keine Gebühren, BTC-Cashback & 150.000 USDT zur Feier der Krypto-Geschichte
a16z: 7 Grafiken, um zu verstehen, wie Tokenisierung die Natur von Vermögenswerten verändert

